
成为信息文明的主人翁
2024/03/25像素、比特、原子——成为信息文明的主人翁
中国企业家之所以能够通过过去几十年的奋斗,为社会发展创造出如此成就,得益于几十年前所拥有的创新精神和思想,以及与当时社会发展阶段相匹配的知识和社会环境的助推。但是时代发展至今日,很多成功的企业家反而容易陷入焦虑。为什么?因为时代在进步,虽然大家的理想、信仰、抱负、能力、勇气足够再次承担起改变世界的使命,但是欠缺了与时俱进的知识,也因此失去了对于时代发展特征的敏锐观察与体会。
人们可以看到很多对当下技术进步的判断,大都有其深刻的道理。但不可否认的是,人类社会进入了一个“不知道不知道什么”的阶段,大家都进入了无人区,都在“盲人摸象”,没有人能够准确知道接下来会发生什么。当然,这对于企业家而言,这本不是什么新鲜的现象,如果退回到三四十年前,也是这种局面,也没有人能够预料到今天的结果。当时大家只是横下一条心,敢于认准一个方向去干、去尝试,所以有了今天的局面。所不同的是,当时技术的复杂程度有限,人们的知识水准尚可应对时代的要求。如今,企业家们的创新精神依旧,勇气尚存,只不过在科学与技术飞速发展的当下,每一个人需要更新自己的知识体系,使我们的知识再次与社会发展阶段相匹配,从而能够迎接新时代的机遇与挑战。
接下来,我针对这个观点谈几点心得体会。
第一,概率论和信息论是新时代的四则运算,如果我们不了解概率,不了解信息,就无法理解智能机器的运行机理。机器有自己的逻辑,它不懂人世间的事,不知道物理定律,也不知道食物的美妙,只会用数据算出下一个概率空间的距离(机器是通过数据计算来预测下一个概率空间的位置)。如果我们无法理解智能机器,则会对其能力手足无措;反之,无论机器如何运行,人类始终操之在我。
第二,对于犯错的接纳程度,决定了人类的进步效率。犯错可以理解为偏差,也可以理解为失败。偏差则纠正之,接纳之;失败则防止之,远离之。人类的社会实践如果不能够接纳错误,就无法学习与进步。要依着三错法的勇气(认错-知错-改错),采取“奖一错,防二错,罚多错”的原则,在纠偏中前行,在试错中进化。第一次犯新的错误时给予奖励,因为这等于员工在尝试新的事情;第二次用新的方式解决问题时则着重于防止错误再次发生;多次犯同样的错误,则需考虑采取惩戒措施。这样的策略适应了不断变化的商业环境,鼓励创新和改进。这里的多到底是多少,也无定规,需要通过实践,摸索出时代与事物发展的客观规律。当然,不经过慎思、总结和持续优化的盲目犯错,则是态度与能力的问题,不在此列。对于技术创新企业,需要大大提高容错的阈值。如果是科学探索,就不只是容错这么简单了。科学的探索历程,永无绝对的正确,始终在不断接近真相的路上。
第三,微软董事长兼CEO萨蒂亚·纳德拉说过,“技术行业不尊重传统,只尊重创新”。我们不能总本着“祖宗成法不可变”的想法,也不能总认为技术前辈的伟大无法撼动,能够超越前辈才是对前辈最大的尊敬。
第四,要当心所有由像素构成的消息,这都是机器的强项。在这个时代,不被骗是最大的优势。我们进入了信息文明时代,每天浏览的信息大部分都是由机器生成,在这个过程中,坚定信仰,不被错误信息所误导,且能从海量信息中挑出真正真实和对自己有用的内容是很有难度的,而这也恰恰是智能机器可以帮助人类的地方。
第五,社会需要再来一次有关现代化知识的“扫盲行动”,尤其是数学和信息论。如果我们还是用人的方法与语言去描述机器能力的话,是十分危险的,很容易误导自己。智能机器的性能和能力应该通过概率来描述,如果机器展现出超越人类的能力,而我们对于机器如何产生这些能力一无所知,就可能把机器神化、妖魔化、拟人化。其中拟人化的危害尤其巨大,人类很容易与此共情,从而产生伦理道德的危险。比如给机器取人名,或者设计人形机器用两条腿走路,而不是三根带滚轮或旋翼的支架。其实三角结构更加稳定和节能,滚动的效率更高,远比双支柱支撑和跨步的使用场景广泛……这种用人的观念去思考机器的能力与行为,会局限关于创新、产品设计和用户服务的思考。
概率和统计——机器智能的来源
“KL散度”是一个在机器统计学习领域非常流行的公式,可以用于评估生成模型所产生的数据分布与实际数据分布之间的差异程度。对于机器而言,无论生成下一个字符,还是生成下一个像素,或者生成下一帧视频,都可等价为在某个多维概率空间内选择下一个概率距离上的数据。以“亚布力”为例,机器会基于某种算法模型将“亚”表示为一个多维数字向量,然后根据算法模型得到“亚”与“洲”的相关性可能是80%,与“布”的相关性是32%,下一个生成的文字就可能是“洲”;但如果我们在输入给机器的上下文中体现了“冬天的东北”这个背景知识,然后再输入“亚”,那么机器计算出下一个字是“布”的概率就会变大。其实,机器并不懂“亚布力”这个概念,它只会依据输入和从数据中训练出来的模型,计算出更大概率的相关信息。
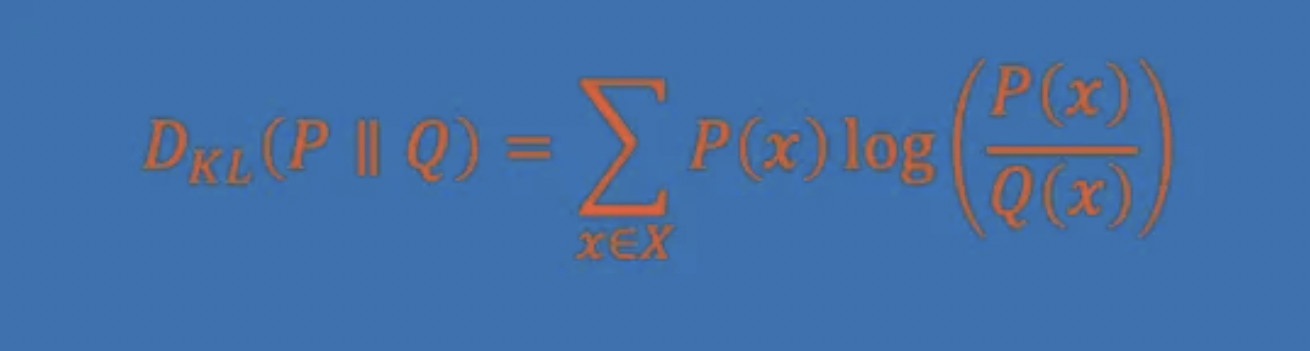
不论是文字、图片还是视频,都具有概率之间的相关性。无论是符合人类常识的生成内容或创造力,还是违背人类意愿或破坏物理规律的幻觉,都是概率智能机器能力的一体两面。

当我们在说机器有幻觉时,是在以人之心理和语言猜度机器的行为。这不是不可以,只要人类经过专业的培训,能够区分机器与人类的不同,就像孙悟空三打白骨精一样;否则人类自己容易把机器神话、妖魔化或拟人化,搞得神神叨叨,人机不分。比如,一个模型可以通过概率的方法,把模糊的背景转化为一张风景照片,人们会认为机器幻想的结果和他们想象中的一样,会感叹机器作画的能力真厉害,但其实这只是概率的问题。
我们要理解概率,要理解人世间有太多的事情仅靠符号就能产生相关性。一旦明白这个道理,就会形成新的技术信仰。如果神化、妖魔化和人性化机器能力,那么未来企业发展和人类社会的发展会受到阻碍,人类文明将没有前途。人就是人,机器就是机器,人工智能是人们用数据喂养、训练出来的。这也在侧面说明,如果没有供机器学习知识的优质数据,即便有再强大的算力也不行。
能指—所指——“描述的囚徒,还是意义的主人”
今天很多人面对的挑战是现有知识体系落伍了,无法理解新生的技术现象。其实这类知识并不高深,我把它们称为信息时代的四则运算,不同的是这里面包括能够表征各种世界现象的线性代数和表征变化的微积分,还包含与人类语言能力相关的一个基本问题,即“能指”和“所指”的关系。这些知识通常在大学教育中都有涉及,之所以被认为深奥,更多是因为在之前的社会文明范式下,人类并不需要这些知识也可以生存得很好。但在这个以智能机器为代表的信息文明中,如同人类社会从农业文明发展到工业文明时需要不同的知识结构一样,这些在工业文明下的知识任选项,变成了信息文明下人类知识的必选项。
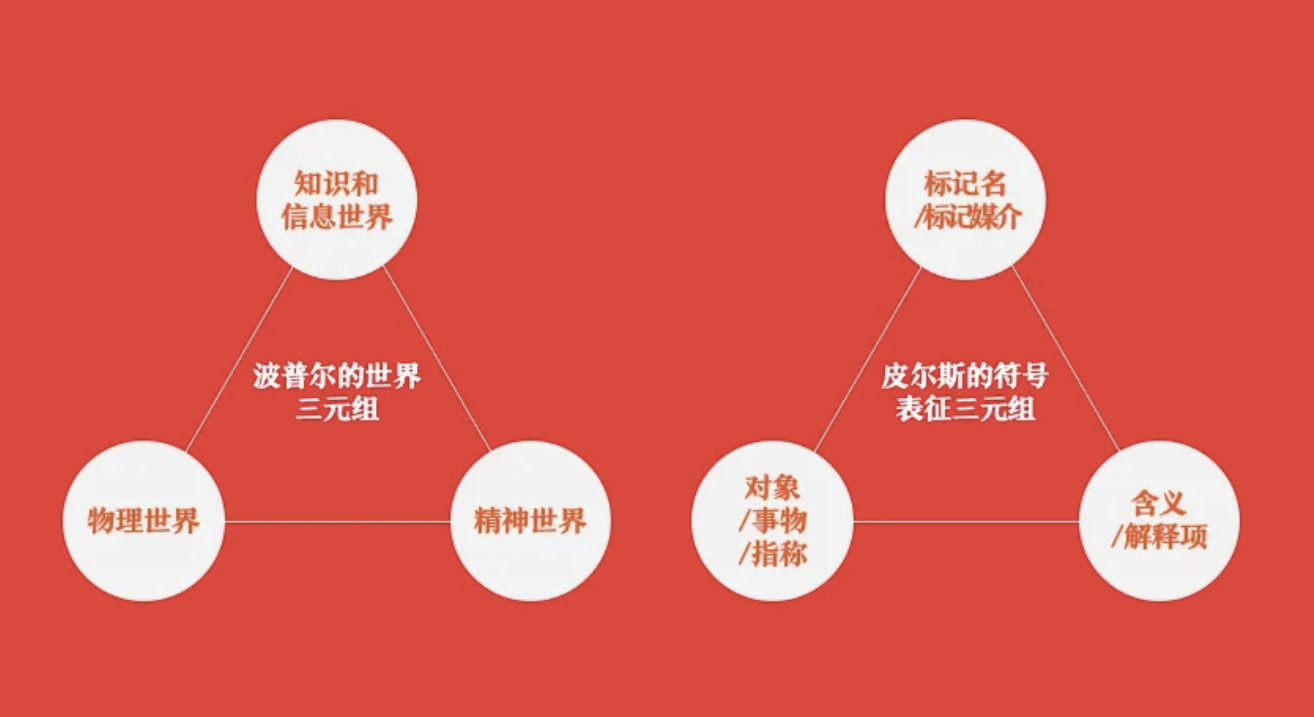
在波普尔(卡尔·波普尔——批判理性主义创始人)的世界三元组里,分为“物理世界”“知识和信息世界”和“精神世界”。而知识的表征则表现为皮尔斯(查尔斯·桑德斯·皮尔斯—美国哲学家)的符号表征三元组,就是“对象”“标记名”和“含义”。
机器学习的过程,就是通过符号学习“能指”,但并没有证明它能够或者需要具备语言的能指背后的所指(能指是一个词语的符号性表示,所指则是它代表的具体实体或概念)。也就是说,能够计算的机器,以概率的方法通过处理海量优质的数据,计算出对物理世界现象相关性的模式识别能力。
在这个过程中,我们会因技术进步,发现无论是表征人类思想的语言、表征世界图景的图像(和视频)还是表征天籁/地籁/人籁(《庄子·齐物论》)的声波,在转化为数据后,在时空域内都有人类尚无法察觉的概率相关性,如果理解得当,人类会形成并加强一种新的技术信仰,从而加深人类对宇宙本质的理解。但是需要注意的是,如果人类无法理解智能机器通过能指而学习到的知识和因此表现出的能力,无法认识到智能机器不是按照人类的思维所想,它是通过计算得出结果,那么不经意地以人类熟悉的概念语言描述机器的能力与行为,很容易对人类的三观产生误导。
我认为,接下来真正的机会在于,当机器能够帮助人类做很多工作时,人们就开始有精力、有能力去思考人的终极三问,并了解“极大”宇宙和“极小”量子的未知。在信息时代,人应该有“四商”,即智商、情商、理商和信商。关于网络安全领域里有句话叫:计算机网络信息安全需要“零信任”,指的是要默认所有进入计算机的信号都可能是恶意的网络攻击。同理,人类摄取信息时同样需要采取“零信任”的态度。如果不做真实性与相关性的判断,我们的大脑就会被真假虚实混淆的信息养肥,但是没有肌肉,没有思考力。因此,我推荐一本书叫做《理商》,它是由基思·斯坦诺维奇和理查德·韦斯特共同撰写的书籍,这本书系统地探讨了理性的概念、理性与智力的区别、理性思维的认知模型,以及评估理性的方法和科学原理。
大多数现代人,包括我自己在内,在当前海量的信息数量冲击下,思考能力和专注度在急速下降。我们不停地被机器生成的信息喂养,如同身体摄入过多食物会造成肥胖症的道理,我们需要把控大脑摄入的信息数量和质量,把大脑瘦下来,去想该想的,听该听的,看该看的。
应对
在《Mission: Impossible - Dead Reckoning Part One》(电影《碟中谍-致命清算(上)》)中,卢瑟对伊森说:“不能拿人的想法去跟机器斗,要用机器的想法去思考”。我对此深有体会,我认为人类掌握智能机器的方法是从机器的角度出发,换位思考以理解机器能力与行动生成的机理,从而始终掌握应用机器的主动性。
大家谈了很多关于算力和算法的内容,我认为有两个非常重要的因素决定了企业是否能够充分发挥智能机器的能力。一是企业里有没有人才能够理解智能机器的能力生成机理;二是企业有没有足够代表企业特征的优质数据。如果缺少这两点,就算有再强大的算力和再好的算法都无法发挥作用。

如图所示,人们从早上睁眼起床到晚上闭眼睡觉这段时间里,会经历很多事情。在每个环节中,我们用橙色代表由人来完成的事情,蓝色代表由机器来完成的事情。在未来,我认为蓝色部分会变得更多,但人会把握主动性。也就是说,机器还是一个Copilot智能副驾,人始终要对机器的行动保留最终裁判权。机器从人类工作、学习和生活的数字化改革过程中获取优质的相关数据,经过计算提取出知识,再根据这些从人类行为中能够学到的知识指导机器的行动。
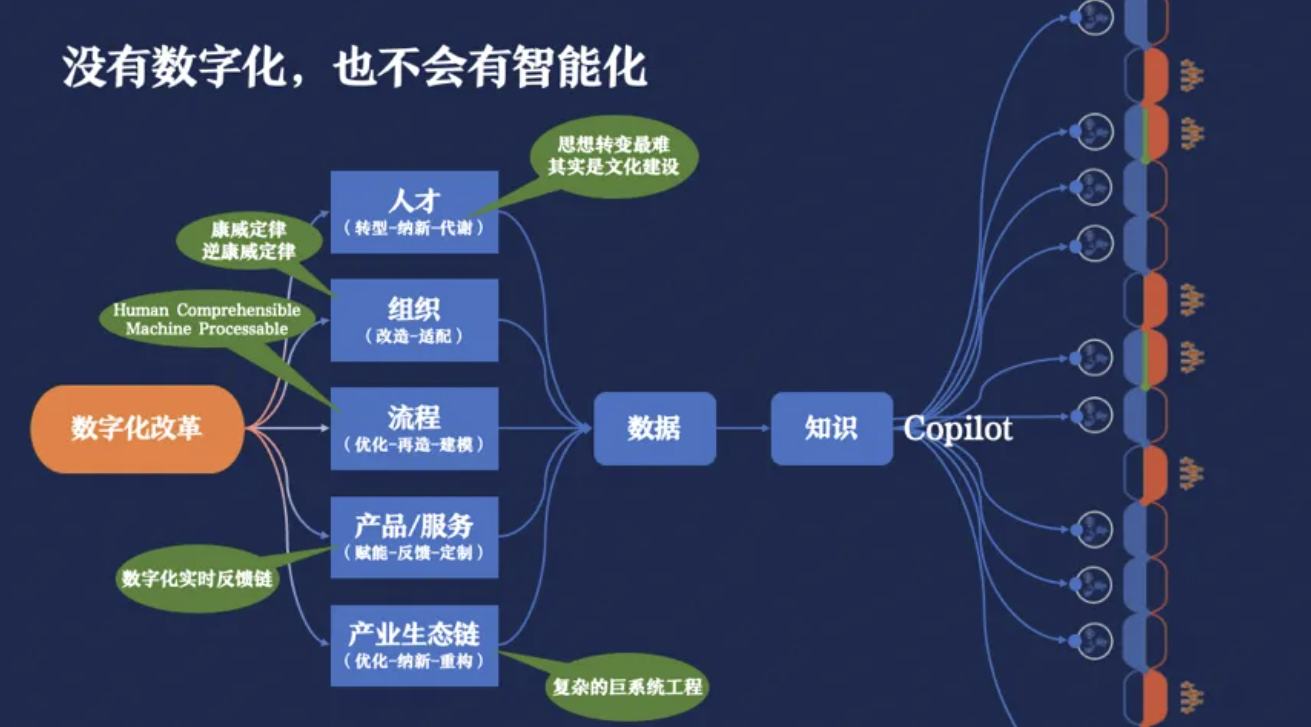
没有数字化,也不会有智能化,但目前我们的数据质量还不够高,还不够多。当我们要成立一个AI原生企业时,首先要确保数据结构是AI原生的,同时,人才、组织、流程、产品和产业链一个也不能少,最后,Copilot会将数据知识注入进刚刚提到的所有环节里。我认为所有企业的当务之急,除了人才培养和数学能力提升以外,就是继续进行远未完成的数字化改革。
萨蒂亚·纳德拉曾说过,“对人类社会方方面面仿真后的遍历”是这一轮机器智能的能力特长。这句话非常抽象,但一语道破天机。机器能够做的,是在人类知识范畴内通过对人类知识的仿真之后遍历所有可能性。从人类在有限的精力与寿命的约束下找到本地最优解,或者撞大运找到全局最优解,到机器基于人类知识把更多的可能性仿真模拟一遍以找到全局最优解。好比机器帮人类把地球上所有的山爬一遍,找到风光最好的一座山。靠人这一辈子,很难遍历所有可能性。
对很多企业家来说,真正的未来不在于算法,不在于大模型,那种成本和资源投入只有国家级或者世界级的大型组织可以承担得起。但是,智机原理、认知科学、量子物理、天文科学,以及由此衍生的智慧城市、智能工厂、智能教育、智能医疗等话题,都会因为大语言模型而重新回到企业的视野。为什么这么说?在农业文明时代,给你大数据是没有太大用处的,但是进入信息文明时代,拥有大数据之后很多事情就可以重新再做一遍。AI其实就是一个智能机,是帮助人类利用已知、探索未知的助手。
在山脚下,别花太多时间想象山顶的风光,咱们共同要做的,是定下心来,努力学习,努力尝试,努力进步。人,没有那么糟糕;咱们,也没有那么不争气。
总而言之,我们要与不确定性做朋友,要同时掌握“定律”和“概率”;要坚守理性,不要从人的角度理解机器的能力;要弘扬人性,发挥人类的主观能动性、适应力和生命力。我们的未来不是由别人定义的,是由自己创造的。在信息爆炸时代,我们更不要把专注度浪费在没用的信息上,思想一旦跑偏,一旦被牵着鼻子走,就会很危险。
(韦青 微软(中国)有限公司首席技术官)






其他文章
-
“中超”赚钱还是赚吆喝
2017/08/03 -
一带一路与中国企业国际化
2017/04/26 -
人工智能在中国
2017/04/26 -
陈启宇:复星的未来医疗之路
2017/04/26 -
曹远征:去杠杆核心是去“僵尸”
2017/04/26